|
Radchaneeporn Changpun I'm a graduate student in computer science at the Department of Computer Engineering, Chulalongkorn University in Bangkok, Thailand, under the supervision of Professor Peerapon Vateekul, Ph.D. with Titipat Achakulvisut, Ph.D. and Professor Arunya Tuicomepee, Ph.D. as co-advisors. Currently, I am researching about Large Language Models focusing in the area of Low-resouce language LLMs, Finetuning, and Agentic Workflow CV / Github / Linkedin / GoogleScholar / Email / Huggingface |

|
Research
I'm interested in data science, machine learning, and deep learning focused on Natural Language Processing(NLP). Area of my research is about Large Language Models. |
Publications |
|
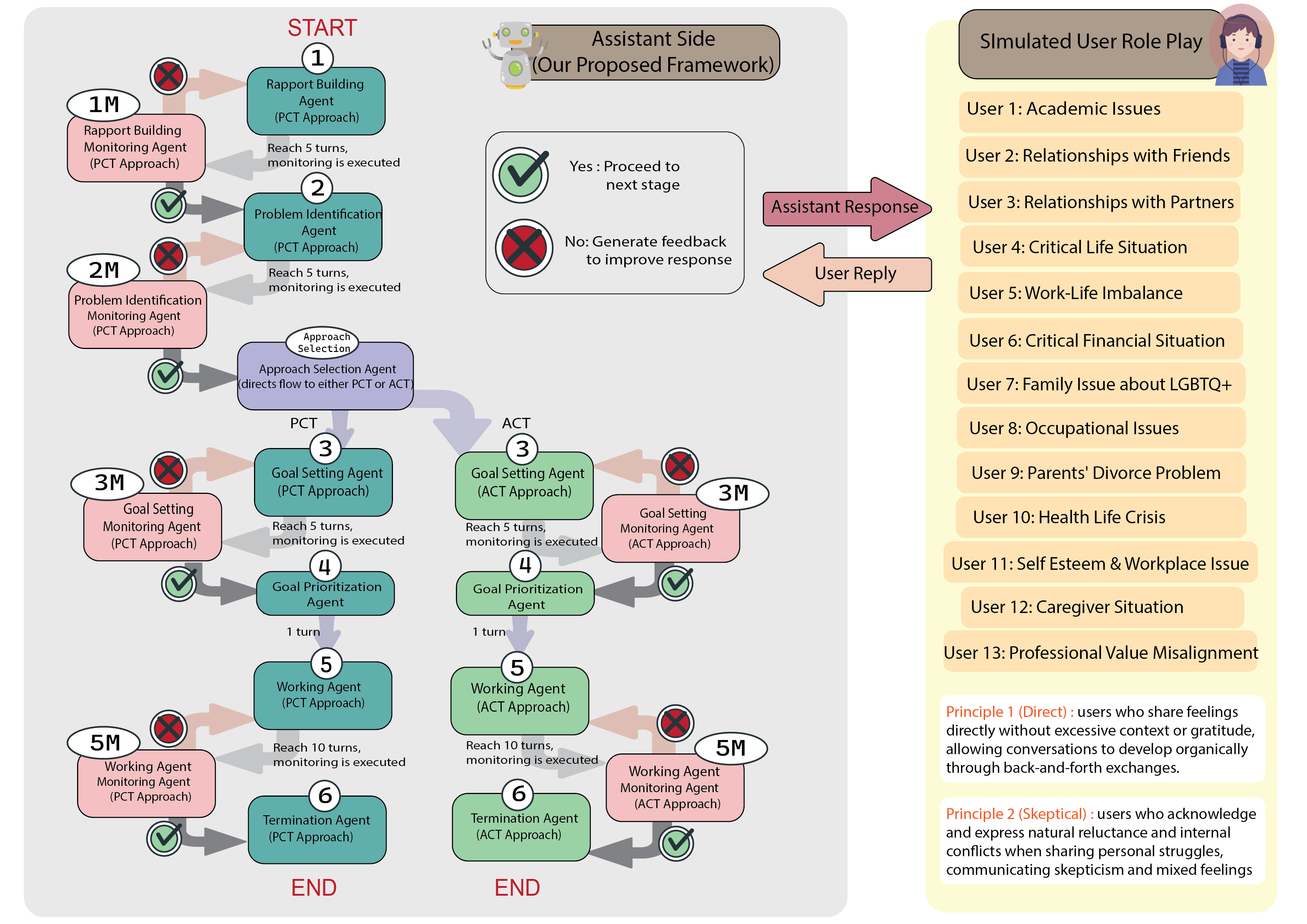
Radchaneeporn Changpun, Naphat Khoprasertthaworn, Pipat Jongpipatchai, Theerin Petcharat, Krittapas Rungsimontuchat, el al. The 20 th International Joint Symposium on Artificial Intelligence and Natural Language Processing Presented on November 2025, 14 Read my paperWe developed an agentic stage-based LLM framework that guides conversations through five counseling stages, drawing from Person-Centered Therapy and Acceptance and Commitment Therapy. Our system uses three specialized types of agents: stage based agent for each framework stage, another one approach selection agent selects appropriate counseling approaches, and monitoring agent manages stage transitions. The framework achieved a 79% positive user reaction rate, significantly outperforming baselines. Real user testing and evaluation by counseling practitioners confirmed improvements across seven of eight mental health support metrics, demonstrating potential for scalable LLM-based mental health support in Thailand. |
|
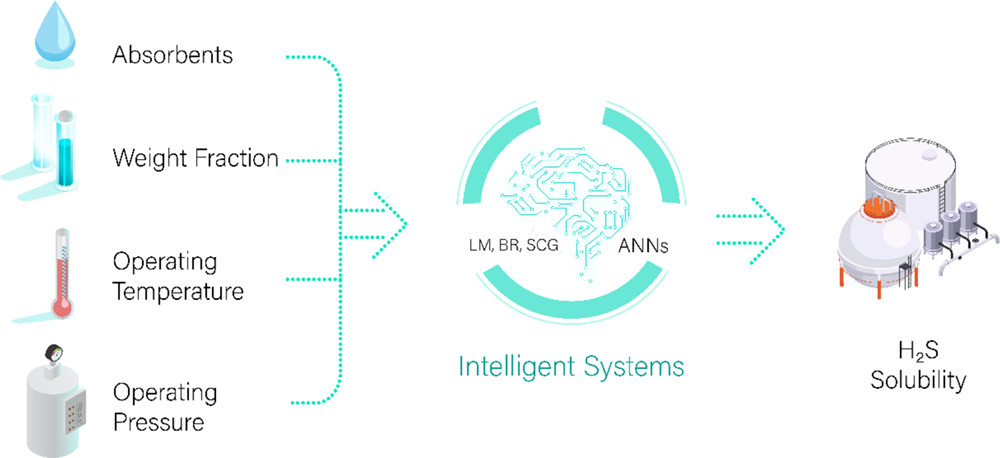
Prathana Nimmanterdwong, Radchaneeporn Changpun, Patipon Janthboon, el al. Link to Paper This publication is about applying a function in the MATLAB program and knowledge of Data Science to develop an artificial neural network model for predicting hydrogen sulfide solubility in natural gas purification processes. The model obtained a coefficient of determination (R2) of 0.9817 and a mean square error (MSE) of 0.0014. |
Projects |

|
LLM based mental health support chatbot in Thai. Currently, Dmind Chatbot is continue researching and developing under Center of Excellence in Digital and AI for Mental Health (AIMET)
|
|
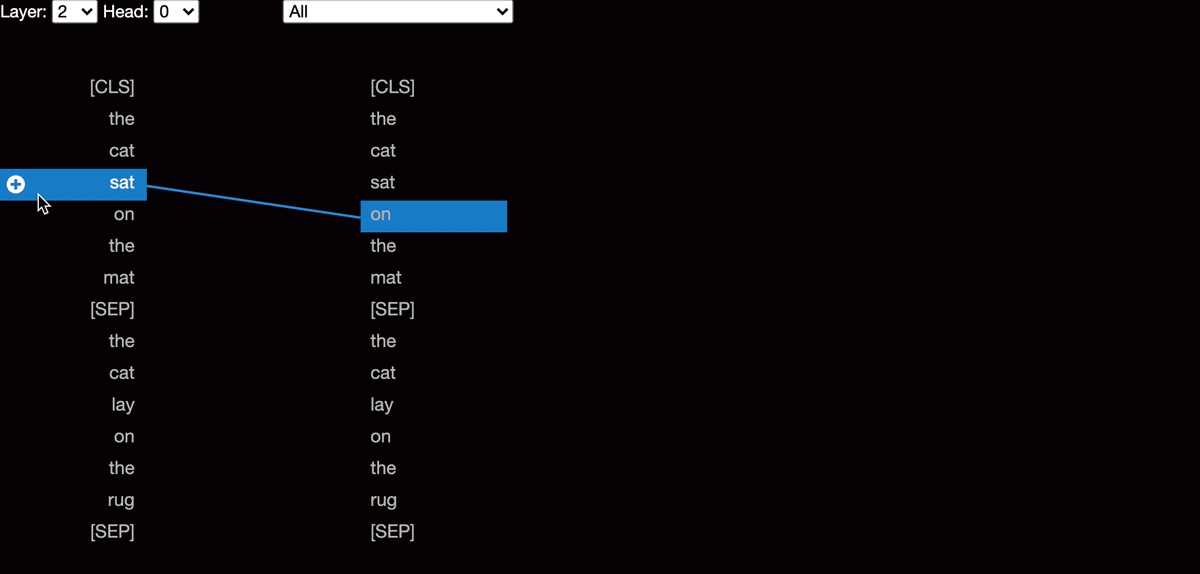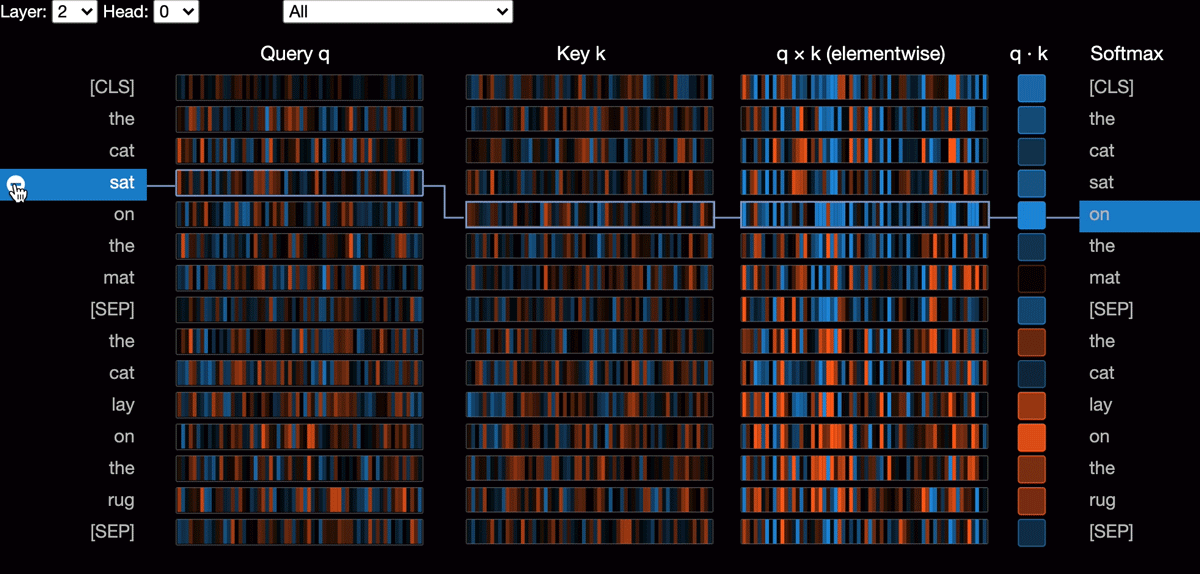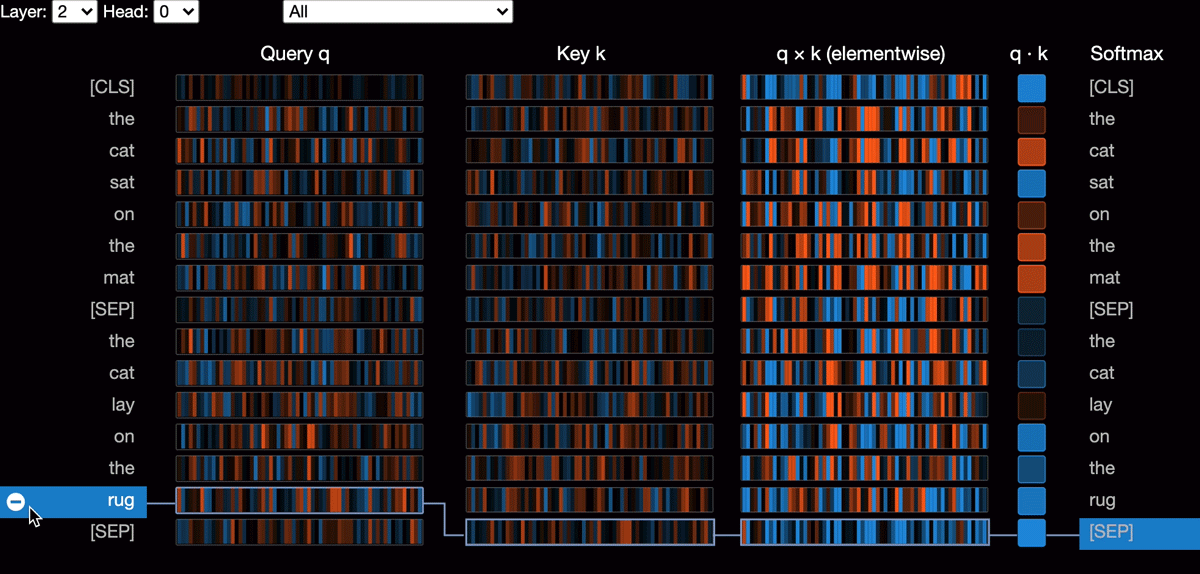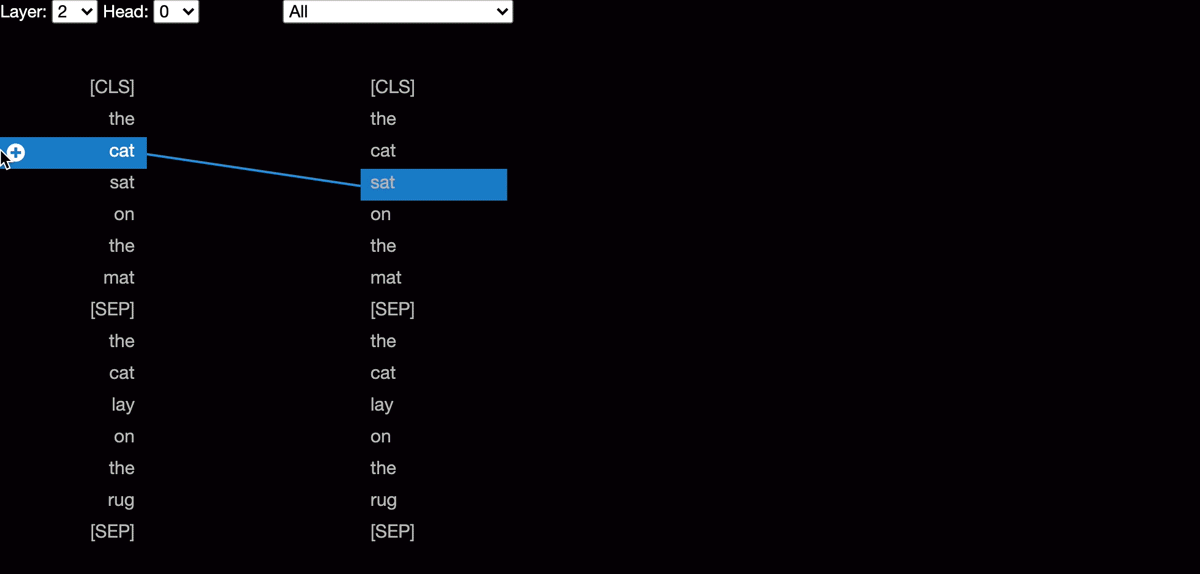
Project Github I classify Scopus publications using encoder representation from transformers language model (RoBERTa), achieving a significant improvement of 40.3% in the Macro F1 Score (0.6687) compared to the baseline model (0.1894), demonstrating the effectiveness of transfer learning in enhancing text classification performance |
|
Project Github This group project conducted an empirical study comparing LLM techniques (agentic RAG, Naive RAG, Long Context LLM, Vanilla inference) for answering Thai Personal Income Tax (PIT) questions, measuring performance with automatic NLP metrics (BERT score, BLEU, ROUGE-L), LLM-as-a-judge, and qualitative analysis |

|
Project Github I developed a RAG technique to improve the hallucination of Llama2-13B using the vector database created from Scopus publications |
My Blog |

|
My blog about my experience and lessons learned during my computer science graduate degree at Chulalongkorn University, Bangkok, Thailand. Read My Blog |
|
Last update: January 17, 2026 This website is adapted from the source code from jonbarron's website. |